Hi, I'm Eric.
I'm a Full-Stack Web Developer with a strong foundation in both front-end and back-end development. I specialize in creating dynamic and responsive web applications. Beyond web development, I bring expertise in machine learning, allowing me to integrate intelligent solutions into projects. As a fast learner and dedicated team player, I thrive on challenges and am constantly seeking new opportunities to expand my skills and contribute to innovative projects. Let's build something amazing together.

Scroll for more
Experience
Software Engineer Intern
May 2023 - September 2023Insilicom LLC - Tallahassee, FLSoftware Engineer Intern
August 2020 - July 2022Insilicom LLC - Tallahassee, FLEducation
B.S. in Computer Science
University of Florida, Gainesville, Fl2025Minor in Business Administration
University of Florida, Gainesville, Fl2025Tech Stack
- JavaScript
- Python
- C++
- Java
- Linux
- Git
- React
- MongoDB
- MySQL
- Docker
- AWS
- Django
- Flask
Languages
- English 🇺🇸 : Native
- Chinese 🇨🇳 : Bilingual
My Portfolio
Web Applications
Nomja
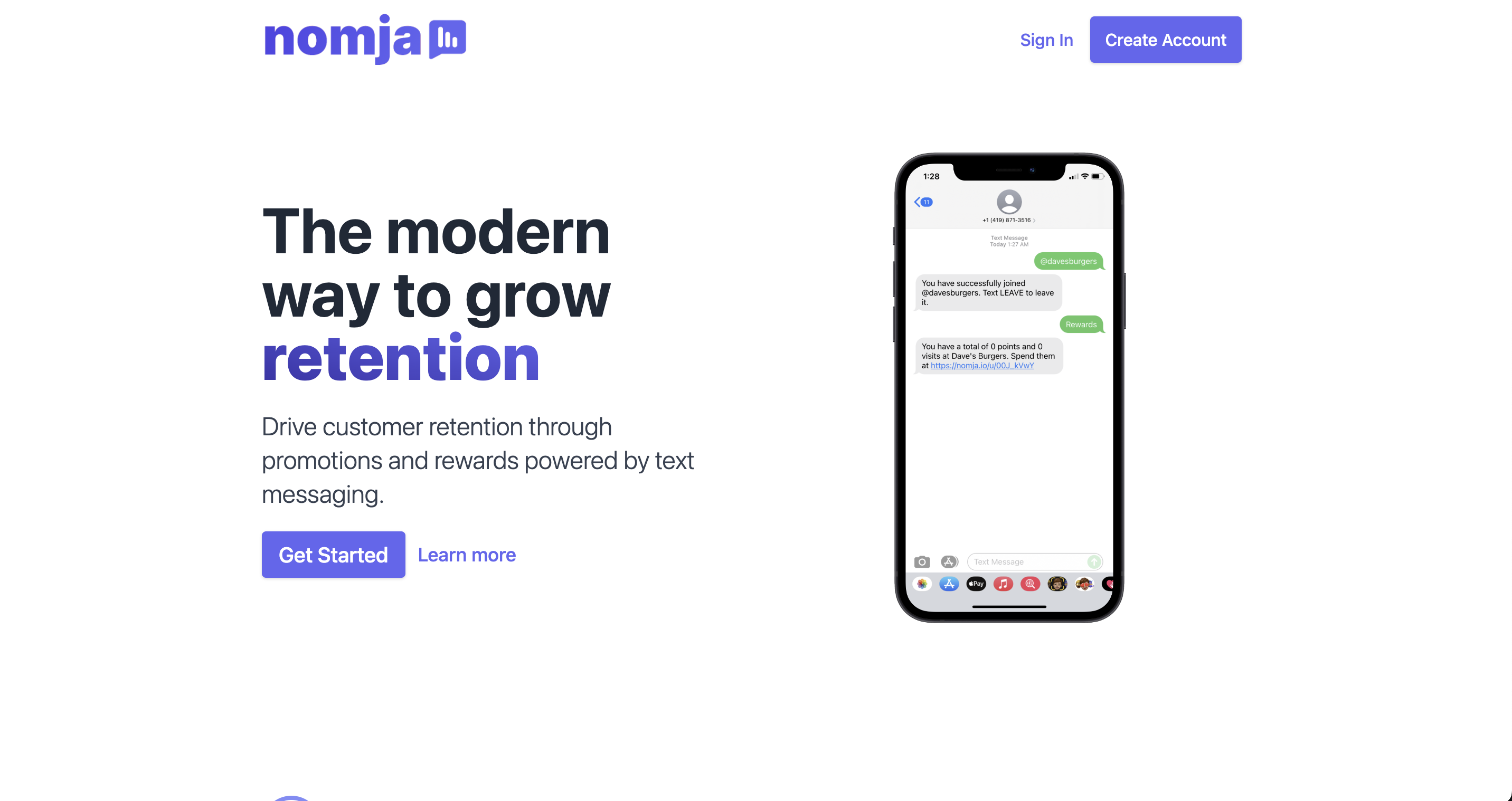
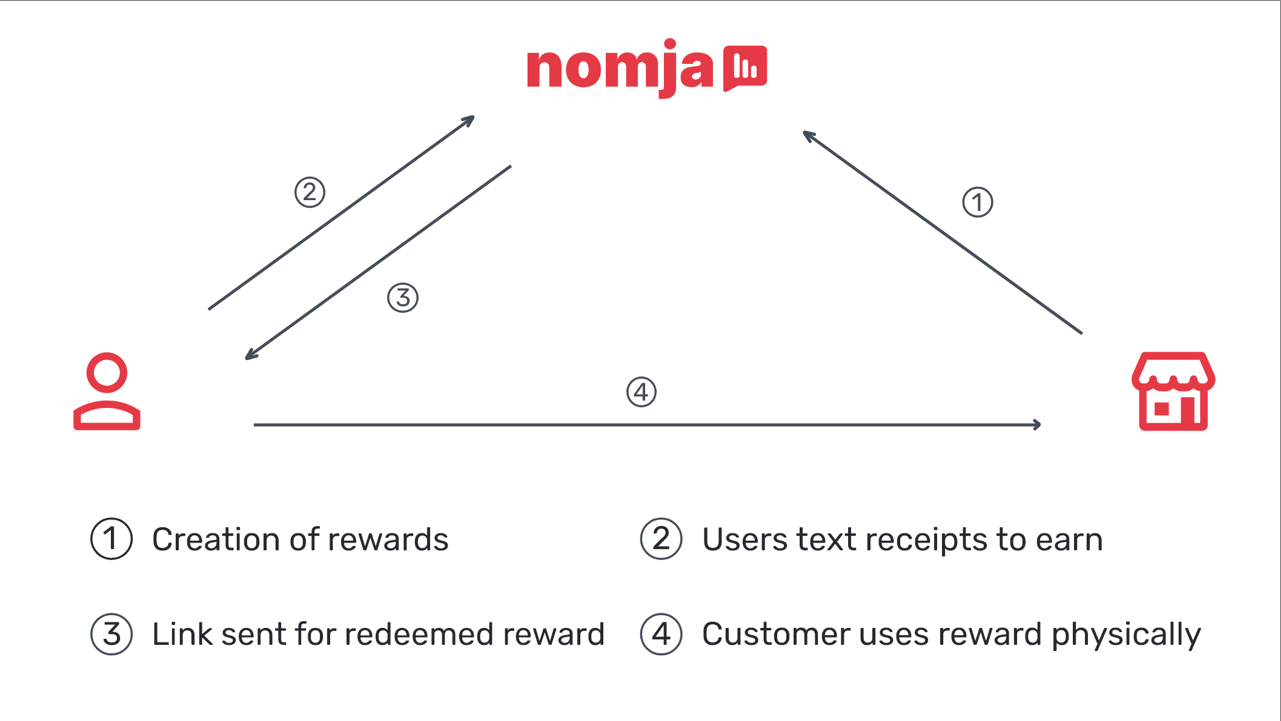
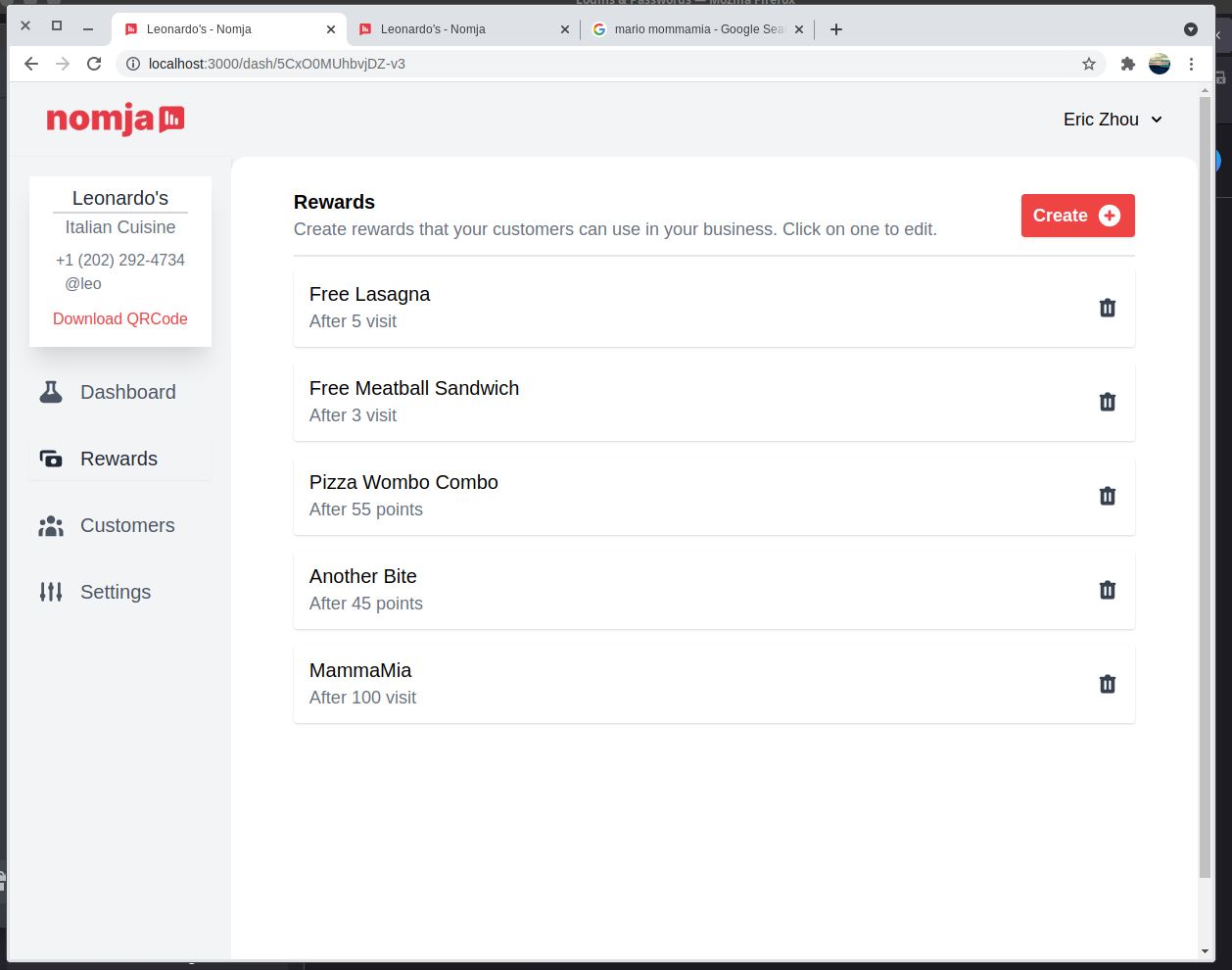
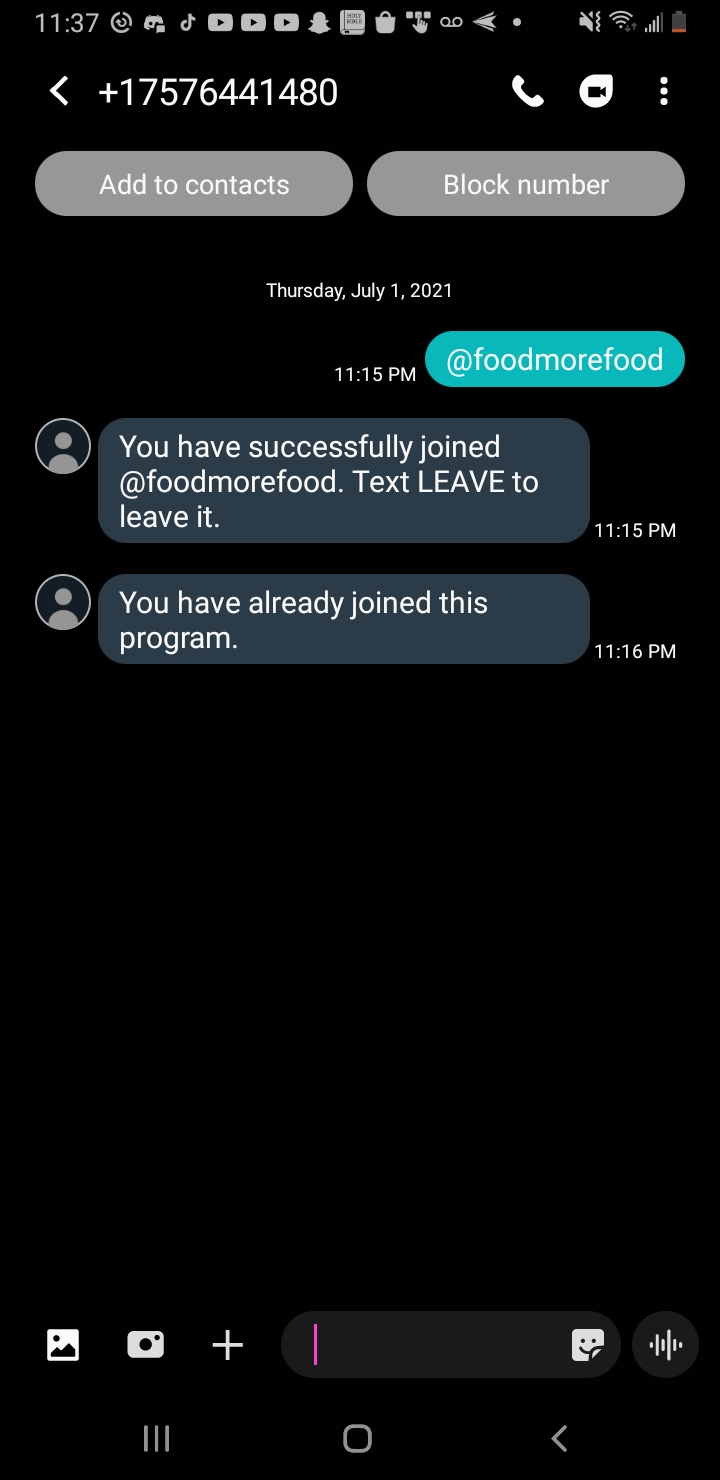

Nomja is a text-based loyalty program for small local businesses. It allows customers to earn points for purchases and redeem those points for rewards. It also allows businesses to create and manage their own loyalty programs.
BioKDE Website
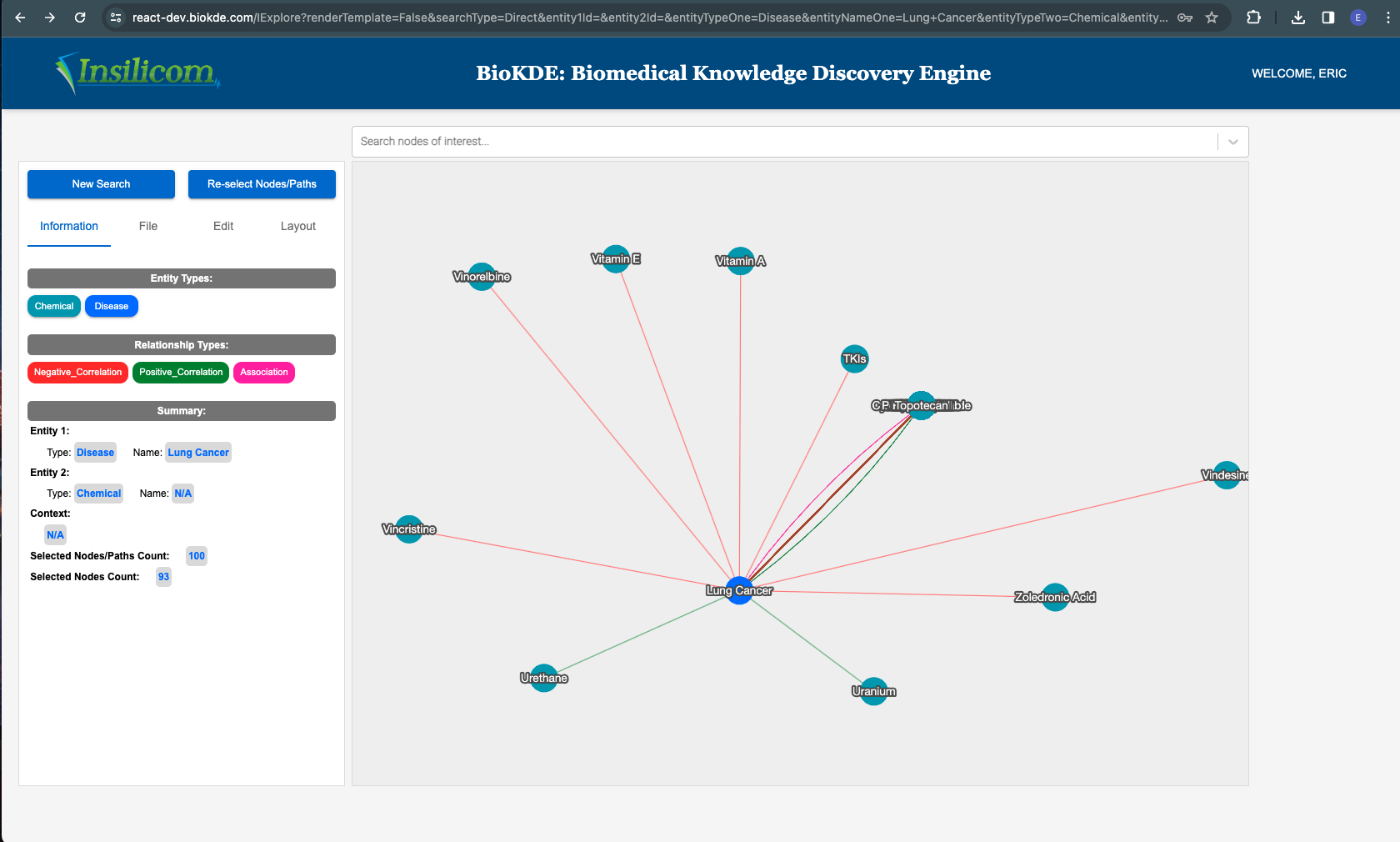
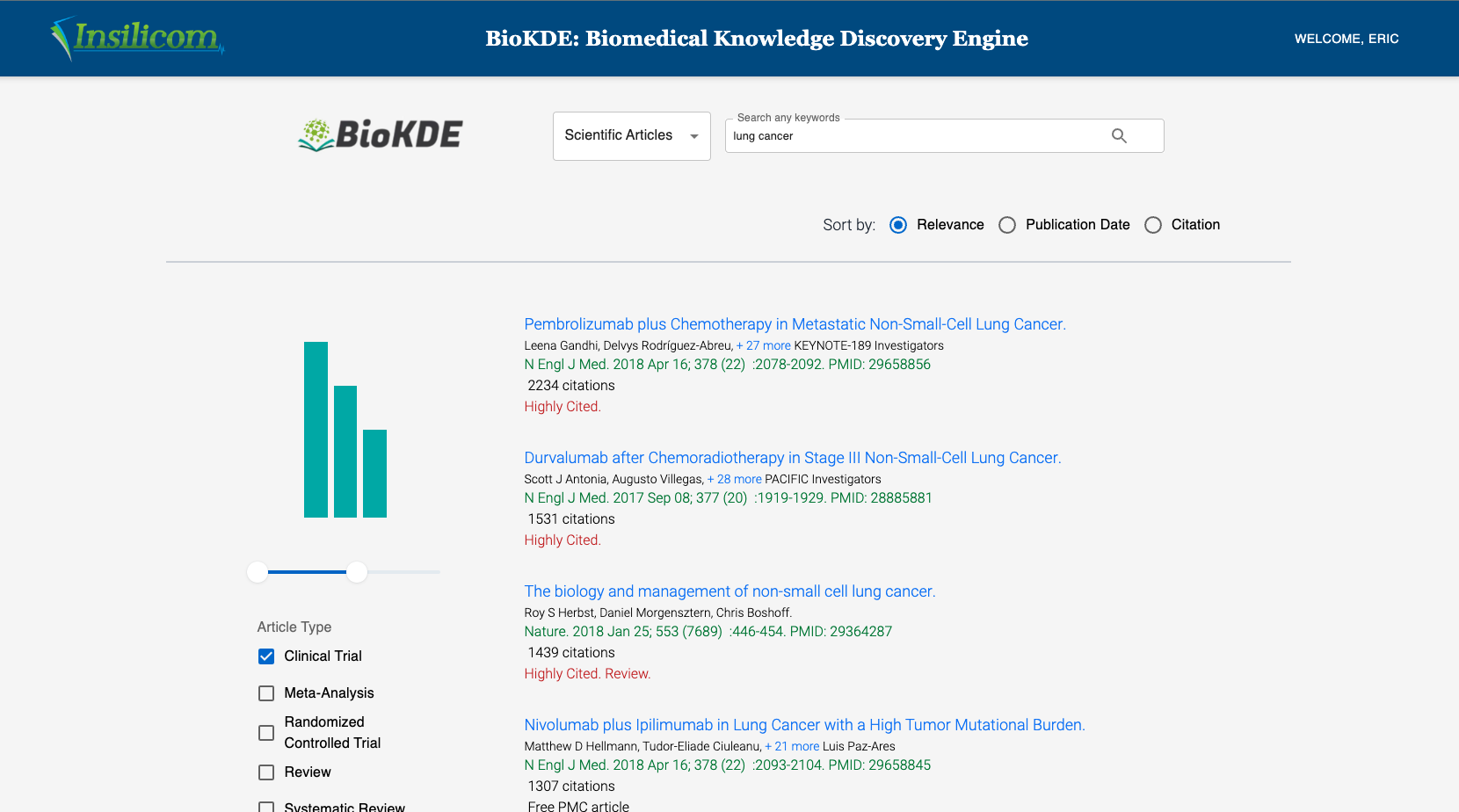
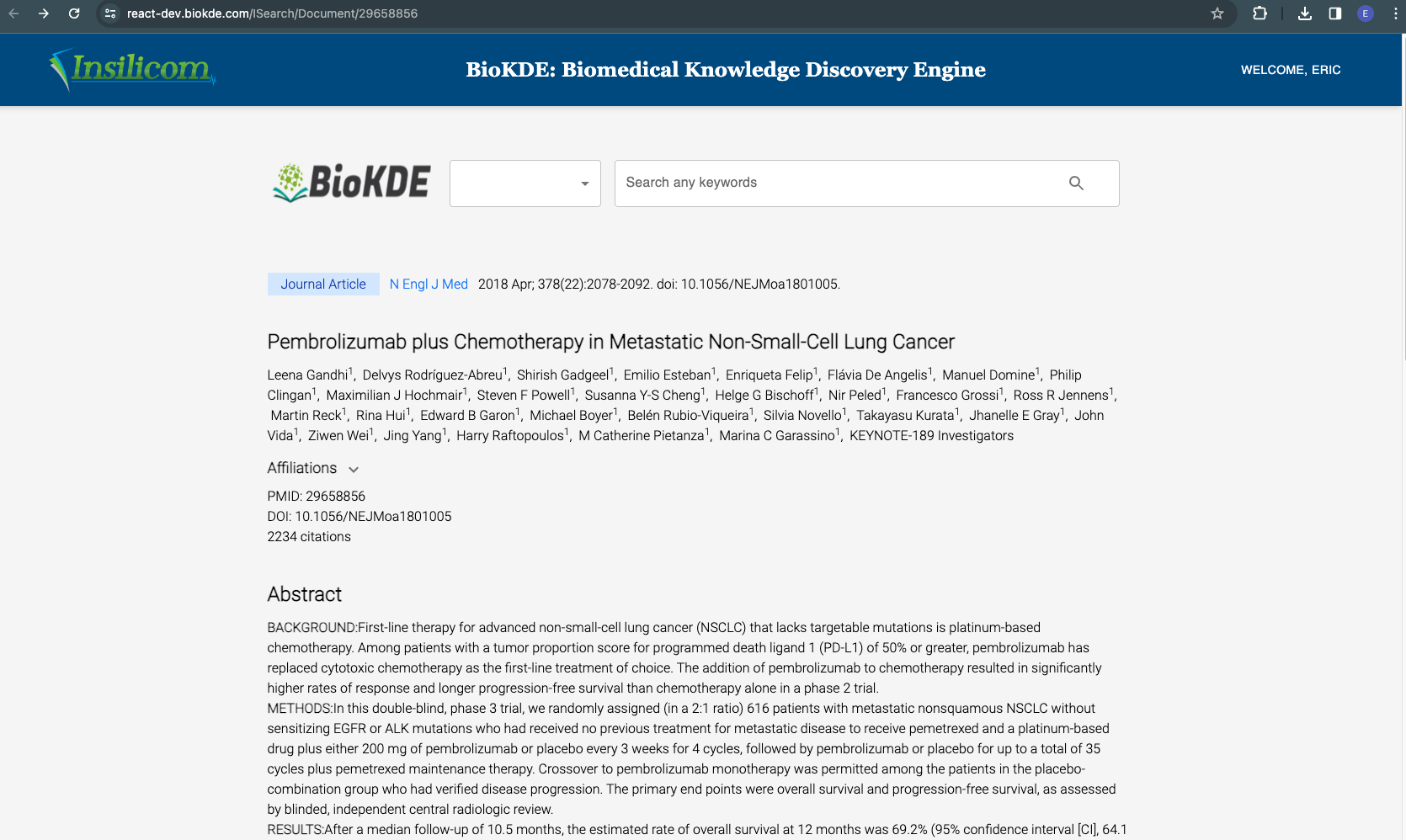
Biomedical knowledge discovery engine (BioKDE) was developed by scientists at Florida State University and Insilicom as a platform for biomedical researchers to retrieve, visualize, manage and mine knowledge in scientific literature. There are two main modules now: search engine and knowledge graphs. I migrated 60% of the website from Django Templates to React.
Scribo

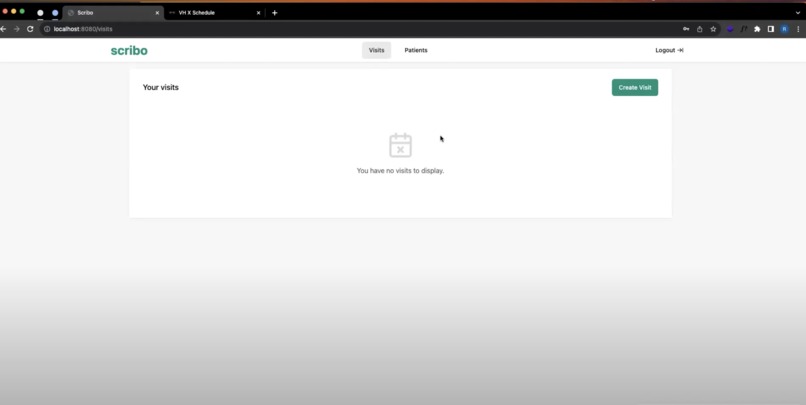

Scribo is a Smart Healthcare Assistant for doctors and patients that is capable of generating Medical Scribe Charts and Transcription from audio recordings of conversations between doctors and patients. Scribo also enables the patient’s Medical Record Organization in one place for both doctors and the patients themselves, while Scribo's smart medical chatbot addresses real-time queries and concerns for the patients as they go over their appointment’s scribe chart and transcript.
NWK Theory
NWKTheory applies the six degrees of separation theory, asserting that everyone is connected through a network of up to five friends. The project visually tests this concept, offering users an intuitive platform to explore and interact within their personal networks. The user's connections are represented as an adjustable undirected graph, color-coded for easy identification of specific connections. A chat system facilitates direct interaction, enhancing the networking experience. The homepage serves as a graph visualization hub, allowing users to search, apply filters, and seamlessly navigate between work and personal connections. The adjacent pages offer profile management and chat functionality for a comprehensive networking experience.
Machine Learning & AI
Biocreative VIII
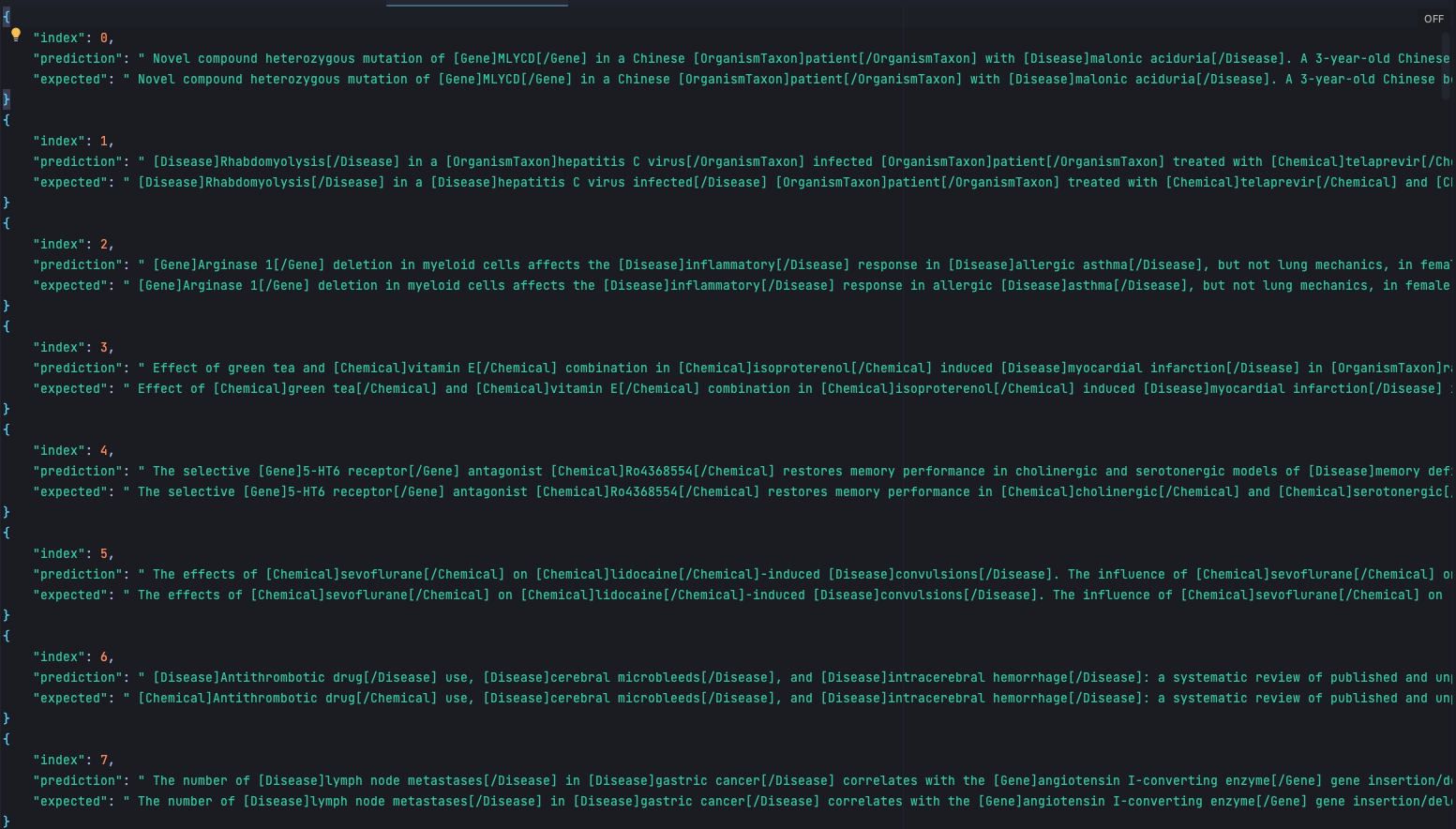
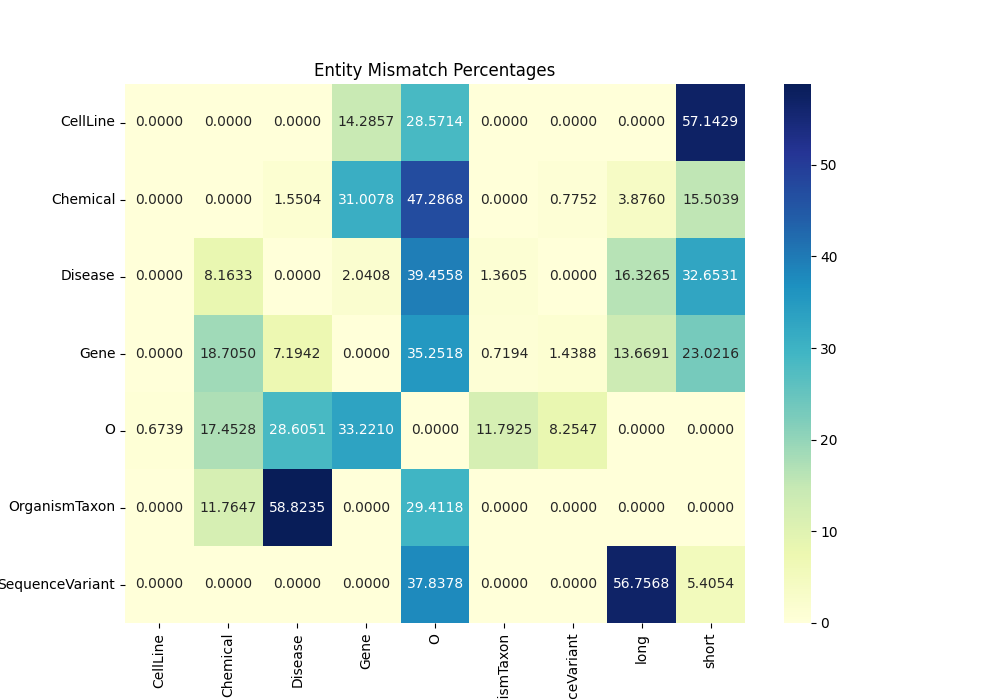
Motivated by the significance of biomedical relation extraction in natural language processing research, this track centers on the automatic identification and characterization of relationships between biomedical concepts in free text. While existing datasets often focus on single-type relations at the sentence level, the recently introduced BioRED dataset addresses this limitation by providing diverse entity types and relation pairs at the document level. Despite attempts, optimal performance on BioRED remains elusive, leaving ample room for improvement. The track aims to spur innovation by offering participants access to BioRED, challenging them to design NLP systems for relationship extraction, and encouraging the classification of asserted relationships as novel findings or existing knowledge. The track comprises two sub-tasks: one focusing on relation extraction and classification based on human-annotated concepts, and the other challenging teams to develop end-to-end systems for identifying and classifying asserted relationships in free text.
Stock Price Prediction
This project uses a Long Short Term Memory (LSTM) model to predict the closing price of a stock using the past 60 day stock price.
Tic-Tac-Toe
This project trains several different machine learning models to play tic-tac-toe.